白話演算法讀書筆記

買這本書的動機
近期的面試風氣開始流行考演算法 ,因此掀起了一股刷 leetcode 的風潮!剛開始沒有甚麼目標性的在刷題, 對我來說能解出來就好了,那時只在意解題的數量 ,認為越多越好, 完全當邏輯測驗在寫,所以刷 leetcode 時 ,很喜歡仰賴 js 內建函式 ,ex :indexOf、 sort、 reduce, 寫得很簡潔然後執行時間也很漂亮,真是皆大歡喜阿!
然而很快我就踢到鐵板了,最近一次面試筆試考到:
請利用演算法將陣列裡的元素由小排到大
然後備註不能用 sort
看到不能用 sort , 讓我呆若木雞,有點像是參加烹飪競賽 ,但開賽後發現我的菜刀被拿走的感覺,直到交卷我都沒有寫出來。
回家重新改一下刷題方式 ,不依賴那些 js 內建函式,只能用 for、 while … 雖然都有用暴力的方式寫出來,不過看到那個慘不忍睹的執行時間和占用的記憶體還是挺挫敗的,心想雖然暴力解出來了 ,但這樣好像失去解題的意義,才意識到我需要認真的去理解一下理解演算法和資料結構,不然那些大量的刷題其實意義不大,就在某一天 ,在天攏書局的暢銷排行榜看到這本書,本來抱持著應該也是會看到睡著的心態翻開這本書, 結果並沒有! 於是花了一些時間整理出部分我覺得不錯的重點。
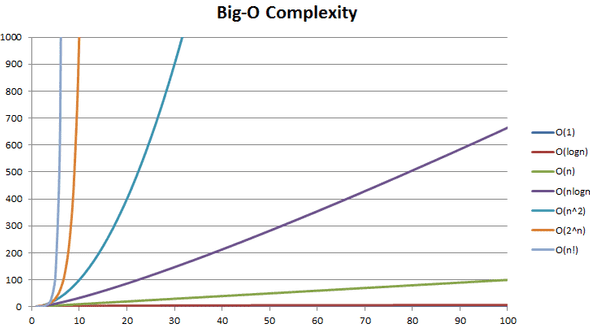
Big O 是甚麼?
- 演算法運算次數的增長效率
- 演算法的執行時間不是以秒計算的, 是以運算次數計算的
- 演算法的執行時間 ,不一定會隨著元素數量的增加而等比增加
O(1) — 只要執行一次
O(log n) — 對數時間
O(n) — 線性時間
O(n*log n) — 快速排序法
O(n²) — 慢速排序法
O(n!) — 階乘時間
遞迴
遞迴由兩部分組成 Base Case(基本狀況) Recursive Case(遞迴情況),Recursive Case 就是當函式呼叫自己本身的情況,Base case 則是當函式不再呼叫自己的情況 ,避免進入無限循環。
二元搜尋法
利用將資料切一半的方式來做搜尋,舉例來說,如果要從數字 1–100 猜終極密碼 ,很不幸的數字剛好是 99 就需要猜 99 次,但如果用二元搜尋法就會是先判斷數字是否大於 50 ,那是否大於 75 ,依此類推每次都用對半砍的方式縮小範圍,最後只需要猜七次就能猜出終極密碼。

時間複雜度為 O(log n)
先決條件必須是已經過排序的清單才能使用
選擇排序法
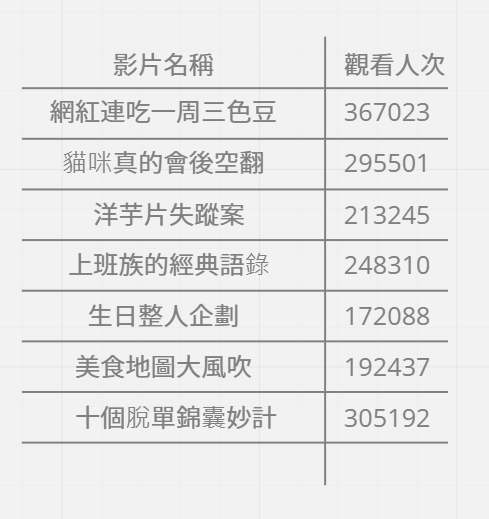
假如有一個影片清單希望能依照觀看人次多寡來做排序,先從原清單尋找最高觀看次數的影片 ,然後放入另一個空白清單,再回到原清單尋找最高人次的影片 ,放入空白清單,重複以上動作,直到原清單被清空為止。
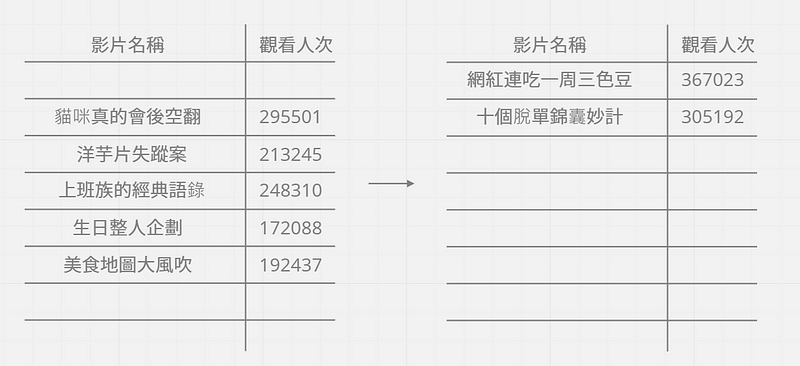
時間複雜度為 O(n²)
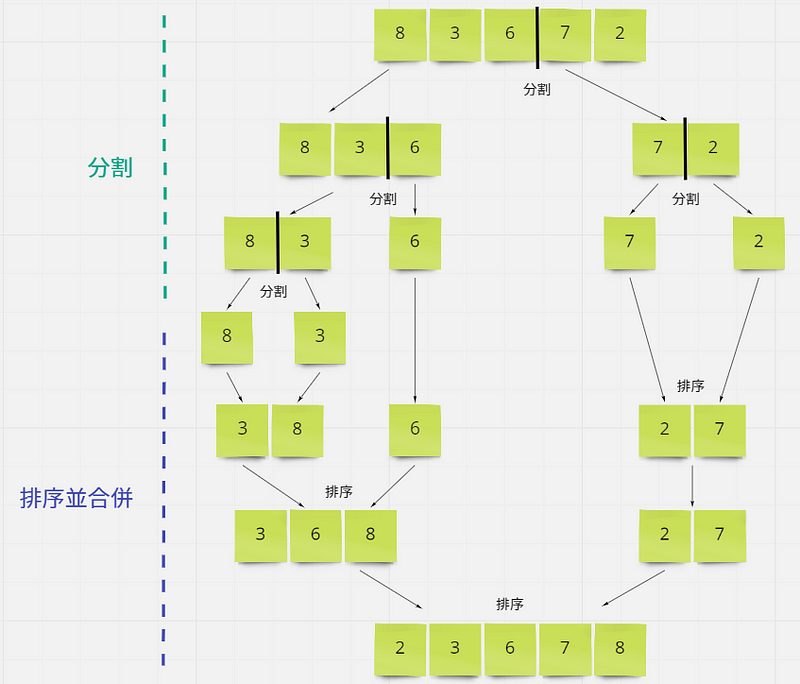
快速排序法
快速排序法的執行速度會比選擇排序法快的許多,先建立一個 qsort 的函式, 傳入的陣列為[2, 1, 3, 5, 4]
函式內部實作為:
- 先從陣列裡取出一個元素為基準值 3
- 接下來準備兩個陣列(比基準值大的陣列[A] 、比基準值小的陣列[B])
- 跟基準值做比較, 比基準值大的值就放入 A 陣列 ,反之放入 B 陣列
若 A or B 陣列長度大於 1 ,則再次呼叫 qsort 函式(遞迴),最後將[比基準小的陣列] 、基準值、[比基準大的陣列]依序組合起來就是排序過後的陣列。
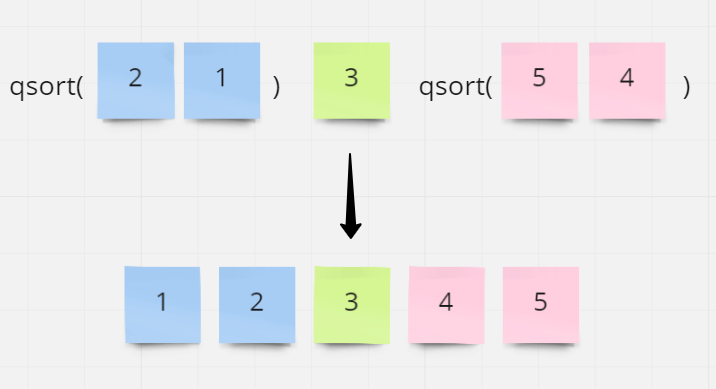
在最差的情況下, 時間複雜度是 O(n²)
平均情況下時間複雜度為 O(n)*O(log n) = O(n log n)
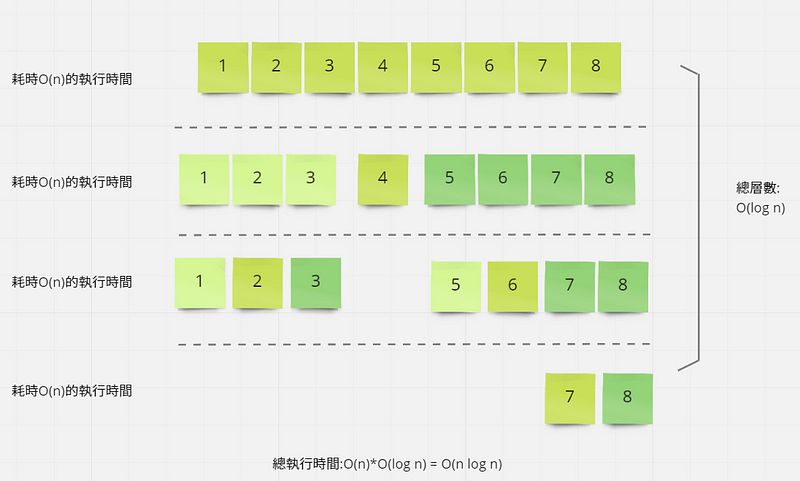
合併排序法
分割到只有一個元素為止,再依序組合起來
時間複雜度為 O(n)*O(log n) = O(n log n)
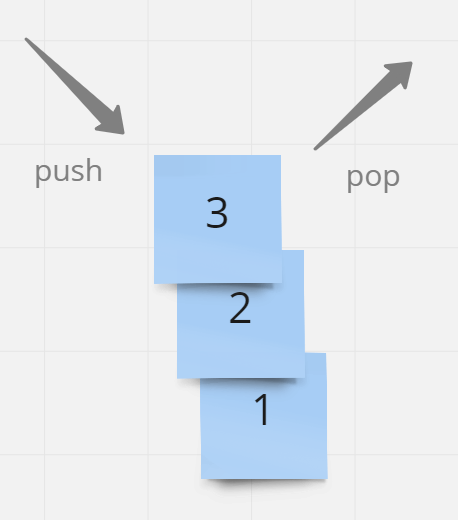
堆疊 (Stack)
是一種資料結構,就像堆疊的盤子一樣 ,堆疊會有兩種操作 pop 和 push。
- 最晚放入堆疊的資料會被最先取出(LIFO Last-In-First-Out)
- 最早放入堆疊的資料會被最後取出(FILO First-In-Last-Out)
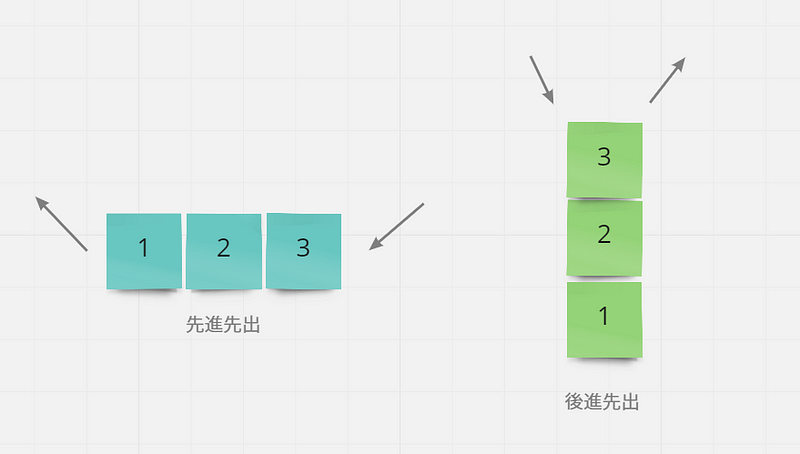
佇列(queue)
只能進行加入佇列和佇列移除的兩個操作 ,佇列是先進先出(FIFO First-In-First-Out),跟堆疊的後進先出是不一樣的。
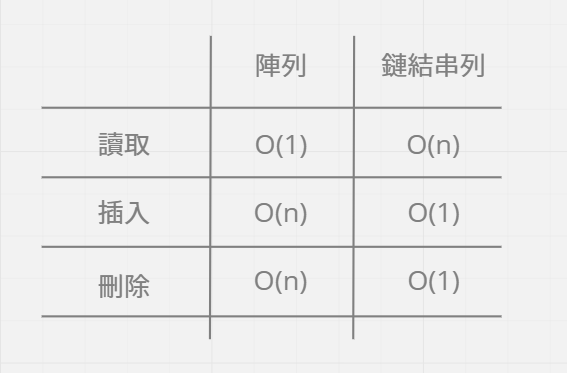
Array(陣列) 與 linked list (鏈結串列)
鏈結串列在存放每個元素的同時 ,也會記錄下一個元素存放的位置,但假設今天想要取得鏈結串列的最後一個元素時 ,就必須從第一個元素開始讀取, 逐一讀到最後一個。
陣列可以直接用索引(index)來取得需要的值 ,不過假如要刪除一個元素或新增一個元素都會影響到其他元素的排序(統一往後或是往前挪)。
雜湊表
又被稱為關聯式陣列,搜尋速度為 O(1)。
適合用在:
- 建立一個元素和另一個元素的對應關係
- 篩選重複項目
- 快取或紀錄資訊 ,以減輕伺服器的工作量
實際運用 : Ex 電話簿、 DNS 解析(將網址轉成對應 IP)
當雜湊表的負載係數等於 1 的時候 ,代表所有的儲存格已滿,容易發生碰撞問題,建議負載係數大於 0.7 時,就要重新調整雜湊表大小。
SHA(安全雜湊演算法)
SHA 函式是雜湊函式的一種 ,會針對不同的字串, 產生一組唯一的雜湊。
實際運用:
- 用來判斷兩個檔案是否一致
- 後端存在資料褲的密碼為雜湊值 ,而非原本的密碼 ,提升安全性
二元搜尋樹
二元搜尋樹左邊的節點值比較小,左邊的節點值比較大。
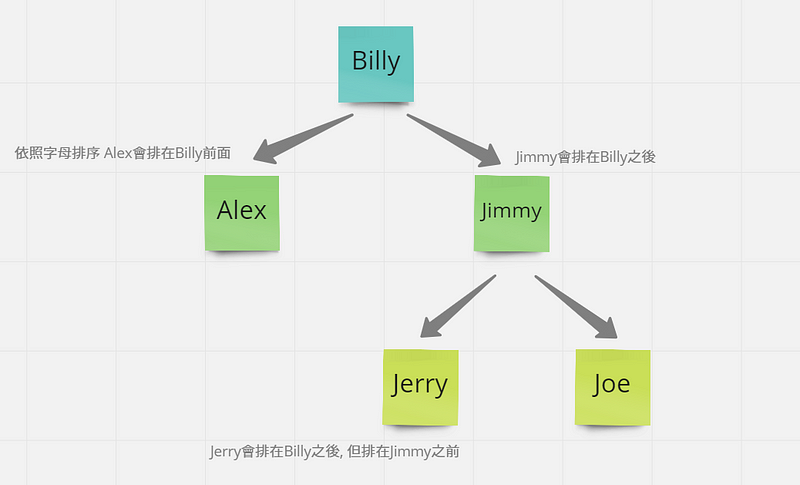
時間複雜度為 O(log n)
進階的搜尋樹
- B- 樹
- 紅黑樹(red-black tree)
- 堆積樹(heap tree)
- 展開樹(splay trees 又稱伸展樹)
Divide and Conquer(D&C)
將一個複雜的問題拆解成多個子問題
以上所有示意圖都是參照書本的範例繪製的
近期買了這麼多工具書,這是唯一一本不會讓我看到打瞌睡或是神遊的書,帶入很多生活情境來解釋理論, 並且搭配很多圖片和生活例子來做說明,艱澀難懂的一些觀念瞬間就通了,雖然是用 python 來實作,不過只要有基本的程式基礎都可以理解,所以相當推薦這本書!
目前在工作實務上還沒用過演算法 ,但必須說可以帶給你不同面向的思考模式,期待有天可以在工作上派上用場。